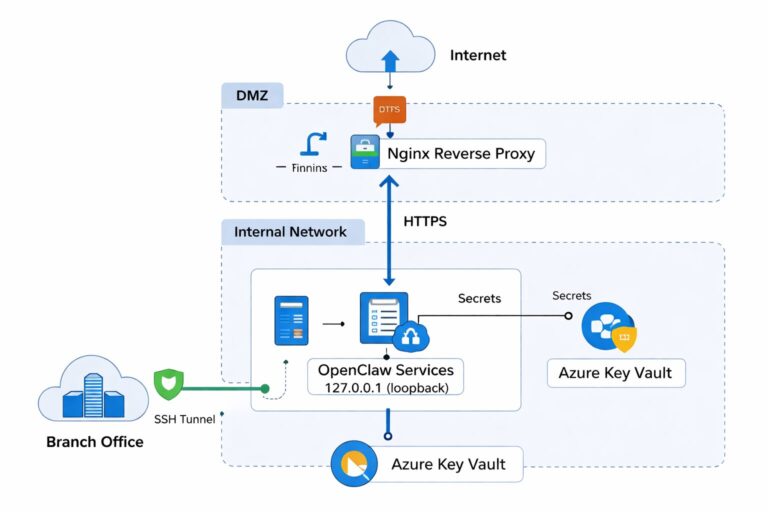
The evolution of ChatGPT technology is rapidly transforming from a simple conversational tool into a core productivity engine for enterprises. While the trend toward smarter, cheaper, and faster large models before 2025 is promising, it simultaneously amplifies issues like AI safety, data leakage, decision errors, compliance audit challenges, and model misbehavior. Many enterprises still treat large models as mere efficiency plugins; however, when integrating customer data, internal knowledge bases, approval flows, code repositories, and customer service systems, ChatGPT’s evolution becomes more than a technical upgrade — it becomes a true risk restructuring.
With prompt engineering standardizing, RAG (Retrieval-Augmented Generation) deeply embedded in business, and multimodal models understanding images, voice, and documents, enterprises are no longer dealing with a single tool but with an intelligent system capable of reasoning, API calling, database reading, generating outputs, and self-optimizing. Sounds exciting, right? However, traditional security boundaries are quietly eroding. The greatest risk is no longer hackers breaking in externally; it is employees potentially feeding sensitive content into models, plugins inserting erroneous data into CRM systems, or models giving high-risk advice unintentionally.
For those focused on ChatGPT evolution, AI deployment, model governance, or intelligent transformation, this article offers a cautionary observation: future large models will represent not just capability competition but governance, architecture, and security competition. Recognizing risks first is essential before discussing growth.
—
Prompt Engineering and Online Learning
Prompt engineering has evolved from simple input instructions to a ‘logical operating system’ layer, including templates, role configurations, context injection, tool calls, and output formatting — essentially becoming business logic that requires auditing, testing, and version control like code. Misconfigured prompts in scenarios such as automated customer service answering can lead to confident but incorrect outputs that masquerade as logical and natural language.
Large model fine-tuning and online learning add complexity, as enterprises want models to learn continuously from feedback and edits. Without strict data quality controls, permission isolation, and rollback mechanisms, errors may become embedded as new
************
The above content is provided by our AI automation poster